Text Analysis
Automatic analysis of a text written in Estonian is more complicated than, for example, automated processing of a text written in English. If we want to find out which words are the most frequent in a text, we should first convert these words to their base form. For example, words like a politician, politicians, with politicians, etc., are different for the computer. But to analyse the content of the text, we usually want to know how many times the word 'politician' appears in the text, despite the form of this word. Furthermore, it is not important to us whether the word starts with a capital letter (at the beginning of the sentence) or with a lowercase letter, except for names.
With this application, you can do two things. Lemmatizing, a function for turning words into their original forms, changes all the words in the inserted text to their base form. In addition to entering your text into the text box, you can upload a file containing the text you want to analyse.
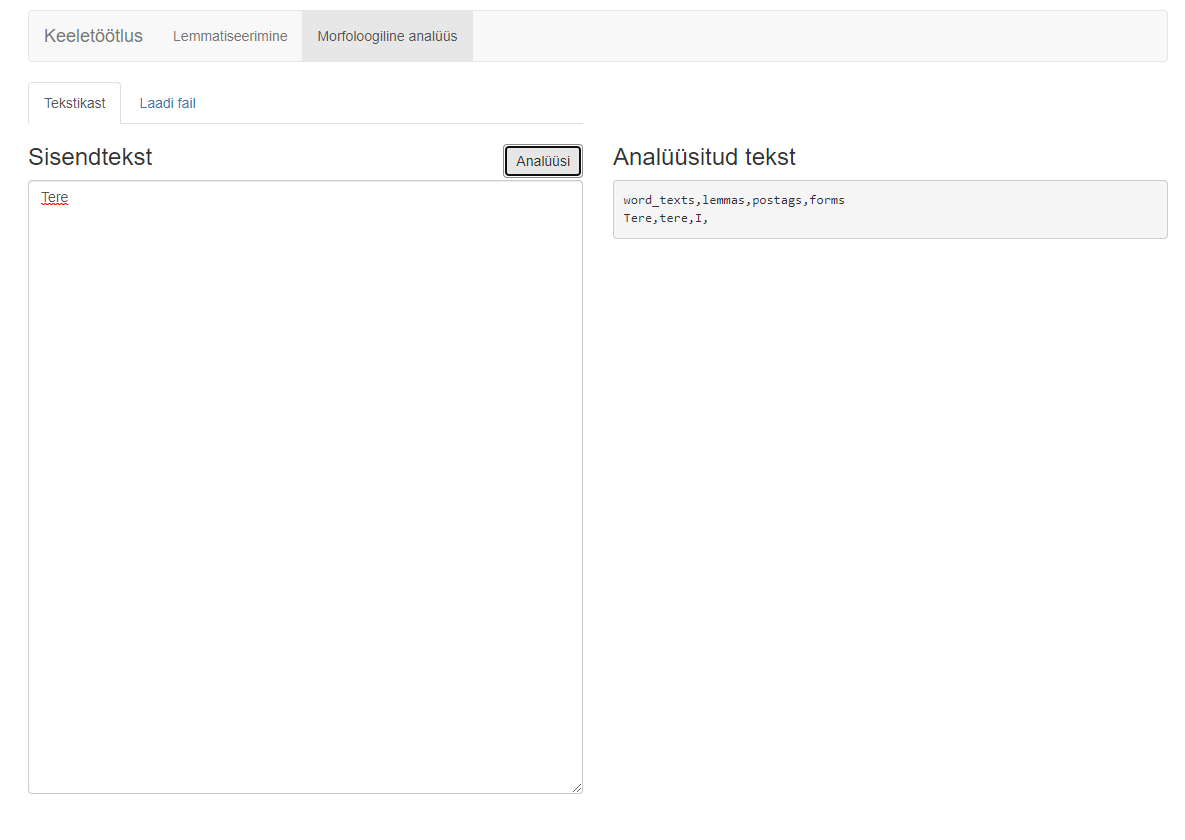
The second function of this application, morphological analysis, adds to each word in the text its base form and its morphological analysis, including its part of speech, case or conjugation, number, etc. It is also possible to input text from your file for morphological analysis, and the output can be obtained as a CSV file where all possible base forms and morphological analyses accompany each word in the text. Commas separate the words, base forms, parts of speech, and analyses.
The text analysis application can be found here.
One example: